This is a post about two experiences I had using Elm. It is quite long, written primarily for the sake of other people who might be considering using Elm – the things that might trip you up etc. I have put quite a lot of content into footnotes for the sake of brevity, so you are advised not to read footnotes unless you want the gory details.
At the very end, however, it gets derailed as I attempt to address what I see as a potential critical weakness in Elm or the Elm community, triggered by some recent events. I tried to separate out these two things into separate posts, but realised that they actually stand together. If you are thinking of using Elm, both parts are relevant.
An upfront summary:
Where Elm is good, it is really, really good. It enables some things that are so hard in other languages you might not even imagine attempting them.
There are significant downsides to Elm. Some of these will probably apply to other frameworks with similar architecture, like React+Redux in some of its forms. Some are peculiar to Elm.
Therefore, you should be aware of these before you start to use Elm, and be convinced that Elm really does solve the problems you have if you are going to persevere.
Sometimes, you should not use Elm. You can use JQuery/VanillaJS [1], and do so without embarrassment or apology. It is the Right Solution to some problems.
Don't be afraid to use Elm with interop of various sorts. Let Elm be good at what it is good at (which is not everything), it's easy to use interop where you need it.
-
Ahem, oops, cancel that last point. The Elm developers have a different opinion to what I express, and are not afraid to attempt to impose their opinion on anyone using the Elm compiler.
Hopefully this is just a growing phase for the Elm community, and a more respectful and mature attitude will prevail.
[I will happily update this post if there is significant change on this front]
To summarise the summary: Should you use Elm? You are an adult, you get to weigh up the risks and decide.
Project 1
I'm not at liberty to give many details about the first project, but it was a small web app, with a few typical things (user registration and login etc.), and then a few CRUD like pages. It was a requirement that all operations should be done with AJAX/REST backend, without the need for page refreshing.
I chose Django and Django REST framework for the backend, which worked great for this project, there was so much out-of-the-box functionality it felt like cheating. I decided on Elm for the frontend, partly as a chance to upskill and learn a modern frontend framework. I had played with Elm before, and done enough programming in Haskell to not be put off by the functional programming side, so this seemed like a far better option than React etc.
I tried to follow this Single Page Application as an example, which was very helpful, and I'll use it to illustrate the things I mention.
My first impression was that for some things there is an awful lot of boilerplate. Wiring everything so that messages get passed to the right place, and JSON decoders to convert all incoming data to something better to work with etc. took a really long time.
JSON decoders are a particularly nasty hurdle to get over. They are almost unavoidable if you are receiving data from your backend, which means you will hit them quite early on in a project, they are very tedious/boilerplatey, and they are also quite tricky to write in some cases, due to working at a higher level of abstraction than you might be used to. In addition, the equivalent code in a JQuery/VanillaJS project is basically non-existent (you can just receive a JSON object and start using it). There are of course big benefits to the way that data is marshalled into your Elm code, but if you are new to Elm I imagine this could be quite off-putting.
Handling of forms was also very discouraging. If I had been doing server side
rendering of a form, I could have done it using extremely little code in many
cases (Django will take your model and generate a form for you that renders
itself to the right HTML and handles input). Writing out the form HTML in Elm
seemed to be very tedious, not to mention un-DRY. Worse, when you've got the
HTML done to the point where it looks right, in Elm you have a form that is
far less functional than you might expect. For every field, you will
then have to explicitly add a field
to the model, a message
to indicate the field was a changed, an onInput handler
to the form HTML, and then add a branch to your update function
to implement recording the data into the model. This is just to get you to the
point of “a form that can remember what it has in it”, before you think about
doing anything with the form data (like sending it over an HTTP API).
This is a lot of work. However, the bigger thought in my mind was “this is just
the Wrong Thing”. HTML and browsers can already do forms really well. They have
already wrapped up that whole "allow someone to type something in a box and
remember what they typed, and give it a name” thing into a component called an
input box, so you don't have to re-implement it every single time, you just type
<input type="text" name="myfield">. The built-in functionality of browsers
plus HTML is getting better, too – you can do more and more things like client
side validation declaratively. Why am I throwing all that away?
In the end I was 500 lines of code and at least 10 hours in. I had some basic page 'routing' set up, and I had a login form that mysteriously did not work (I did not stay logged in), and I was out of my depth in terms of debugging it. At this point, with limited time allowance, I decided to cut my losses and abandon Elm.
I was able to keep the backend stuff I had already implemented, and switched to JQuery and TypeScript for the frontend. I had never used TypeScript before, but it worked really well. With strictness settings turned up to full, it added both a great layer of safety and lots of productivity enhancements in terms of auto-completion (using tide).
For login/password reset etc., I was then able to leverage server-side rendering of forms with just enough TypeScript to get it to submit via AJAX. For other pages I did more client-side rendering. Certainly there were points where the classic JQuery/VanillaJS approach of mutating the DOM brought with it the usual issues of needing to be careful to get the state synced etc., but it wasn't too bad, and it was much, much faster to write.
I was sad that I hadn't got to learn Elm, but it was definitely the right decision for that project given the time constraints.
Project 2
I am not that easily defeated, and I had another chance to use Elm. This was for a side project of mine, LearnScripture.net. Since I do it in my spare time, there were no time limits for this project.
There was one page of the project which had become a nightmare to maintain. It was the 'learning' page, which accounts for about 80% of the time that users will spend on the site, so it is right at the heart of the app, although it is a small fraction of the actual code. While most of the pages were and are server-side rendered using Django, with a smattering of Javascript, this page was heavy Javascript, implemented using classic JQuery style (hiding/showing nodes, changing the contents of some). Some of the state was stored implicitly in the DOM, some in extra module level variables.
I wanted to make sweeping changes to the UI of this page for various reasons, but was afraid to touch the Javascript, with good reason. I had already introduced a set of set-up/tear-down functions for various things that manipulated the DOM into different states, but I was aware that there were still bugs.
I figured this was a project that was right up Elm's street in terms of managing the state. It was also going to be demanding – there were certain interactions that were intrinsically quite fragile and getting them right in Elm might still be hard (this proved to be correct – more on this later). However, there were no classic HTML forms on this page, or other functionality where I thought “the browser/HTML gets me most of the way there, I just need a bit extra”.
This time I was successful. It took me quite a few months working in spare time, and I had a transition period with some beta-testers who tried out the new version and gave feedback, which was essential to catching bugs (including some regressions on the fragile behaviour I mentioned before), and getting feedback on the new UI and iterating a bit. But the new version of the page is now live and the old code thankfully deleted.
I'll describe my experience in categories of things that are hard with Elm, things that are tedious or annoying, and where Elm really shines.
Hard or impossible with Elm
Fine-grained DOM control
Elm makes certain types of control of the DOM much harder.
First I need to briefly describe a simplified version of what my code does. There is a lot of detail in this section, but it illustrates both some of the challenges and some of the amazing things about the Elm architecture.
The page I rewrote in Elm presents a Bible verse to the user for learning. It visually breaks the verse down into words, then progressively hides the words to force you to recall them. Finally it prompts you to type each word (at least in one learning mode). This is done by placing an input box exactly over each word — looking something like this:
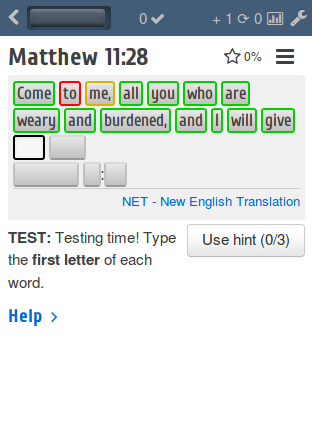
The upshot (once you include all the corner cases I have not mentioned) is you need to:
Update the DOM with the verse split into all the word 'buttons'.
Find the position and size of the word that is going to be tested.
Adjust the input box position and dimensions to match this (accounting for padding etc.)
At this point show the box if it was invisible before (remove
display: none)Focus the input box (
node.focus()).
This is hard in Elm, because you don't get to control the modification of the DOM, it is done by the Elm runtime using the virtual DOM you have provided. You have to wait for the DOM to get updated before you can query it, so doing it all at once is not possible.
In order to move the input box into position and make it the right size, it turned out that the easiest way was to use a port, but even that turned out quite hacky, because ports can run before the DOM is updated. Getting this right and working correctly across multiple browsers sunk a lot more time than in the previous Javascript version, due to the lack of explicit control over the DOM.
There was a further complication. When you focus an input box, mobile browsers
will bring up the on-screen keyboard, which is what we want. This works for a
manual interaction with a touchscreen, and also if you call node.focus(). In
my app, there are a bunch of buttons (“Next verse”, “Practice this verse again”
etc.) which can move you into the 'test' phase you see in the screenshot above.
These all worked fine in the previous version, with the keyboard appearing just
as it should. However, the same was not true in the Elm version.
This might not seem like a big deal, but in my app it was – people spend a lot of time in this interface, and as I tried it for my own usage I immediately noticed this regression, I had to manually focus the input box in order to be able to type. As well as being annoying for me as a user, it was even more annoying for me as the developer – I was not going to spend months rewriting a page just to end up with usability regressions.
It turns out that the cause was this: in some browsers, calling node.focus()
only brings up the keyboard if it is within an event handler corresponding to a
user action, such as a tap/click. The Elm architecture relies on running code
through requestAnimationFrame, and so it does not work. This problem affects both Elm's
Dom.focus command and all code running through ports.
I eventually found a workaround. At the heart of it are two things:
Within Elm, use the generated HTML to indicate the buttons that need to trigger focus.
Outside of Elm, use normal JQuery to add an additional, normal event handler to the buttons that will trigger the focus in the required way.
The complication in part 1 is that I had several buttons that needed to trigger the "show and focus the input box and show the on-screen keyboard behaviour", and, worse, the situations in which they would do so were complex.
Essentially, at the time I rendered each button, I needed to ask “supposing someone clicked this button, what would it do? Would it put us in a state where we now want the input box focussed and the keyboard to be present? If so, add certain attributes that the JQuery code can pick up on which tell it that focussing needs to be done, and tell it all the other bits of data needed to do the focussing”.
In general, this seemed like a hard problem to solve reliably and generically if there is any complexity to your code. Can your code know at runtime exactly what clicking any button in your interface will do, without it actually being clicked?
In the Elm architecture – yes you can! In fact, you already have exactly the
function you need – it is called update. It takes the current model and a
message, and returns the new model. And a message is exactly the thing that
every button already has – when rendering a button you essentially add an
onclick attribute that indicates the message it should send when clicked. All I
had to do was bundle these up into a data structure that looked something like:
and a render function with this type:
In fact I already had both these, but renderButton had to be adapted to take
the whole model (a little bit hacky, but it works). The renderButton
function now literally calls the update function to find out what would happen
if the button was clicked, and if necessary adds HTML attributes to the button
to communicate to the non-Elm world the additional requirements.
This may seem a slightly hollow victory – this code is only needed because of an Elm limitation – but it got me thinking.
At first it seemed utterly magical that I could programmatically know exactly what clicking a button would do to my page before it was rendered. It then occurred to me that this is a really basic thing. Shouldn't any interface we write have the ability to answer such a basic question about itself as "what will happen if I click this button"? Yet there seem to be extremely few frameworks that allow that, Elm being one of them. It is possible in Elm only because every function you write is pure, therefore you can run any function to get a speculative new state, without worrying about potential side effects.
The above technique doesn't include the side effects a button click might have —
side effects are returned as the second part of the return value from the
update function, but in a data structure that is opaque to you – Cmd
values. However, if there were certain side effects you were interested in
knowing about, you could make your update function log these into your model
in some way, as well as sending them as commands. In this way, you could use the
same technique to know exactly what side effects a button would trigger (e.g.
sending an AJAX request) without triggering it.
AJAX retry
A second problem I had was implementing 'retry' for AJAX calls. This was something the previous version had, implemented using jquery-ajax-retry and a few very generic functions, and it had worked well. When an error occurred, or while retrying, these generic functions just reached into the DOM and displayed a visual indicator of what was going on. There was no explicit global state in my code — the necessary state was passed around either through the jQuery plugin or in closures.
When it came to Elm, things worked very differently. In order to be able to retry, and to display messages about progress on the page, I had to explicitly save all the data into my model, and significantly re-structure the app to get everything to work. I could not find any generic, re-usable "AJAX retries" Elm package, and I can't think how it would even work within the Elm architecture — Elm's response objects don't contain the data on the original request in order to enable retry.
Since the different requests had different types in Elm, I couldn't just put them all in a list – I had to create further union types to handle the data for each type of request. Figuring out things like adding delays etc. was all a lot harder and I tied myself in knots with Tasks and types at some points before I figured it all out.
However, the resulting design turned out much nicer. Since I have explicitly captured all the state needed to send the HTTP requests, I can display much more information. I also now have a manual retry button (for when your internet connection goes completely), and in addition I can save all the requests to localStorage before sending, so that if there are serious internet problems, or the page gets closed (or has to be reloaded because of low memory on a mobile app), it doesn't lose any data.
I also realised that my previous code had various bugs in this department – for example, with the old, 'easy' retry code, it was entirely possible for requests to get sent out of order, which in some cases would result in bugs for my app. With the new design, this bug was also present, but fixing it was much easier — I already had a store containing all the outgoing requests data, I just had to turn it into a queue.
Performance
One of the points where my re-development nearly got derailed involved some performance sensitive code. I had no idea it was performance sensitive until I tried to recreate it in Elm. My app uses the Demerau Levenshtein Distance algorithm at one point, and this turned out to be hard to rewrite in Elm. All the optimized versions of the algorithm you can find depend heavily on random access/mutable variables/destructive updates.
This kind of problem is not uncommon. With all pure functional program languages you will hit cases where it is hard or very hard to write efficient code. Both Elm and Haskell suffer from the problem that creation of intermediate data structures can cause a lot of overhead and harbour non-obvious allocations that cause your algorithm to have vastly worse performance than you expect (including changing O(n) code to O(n²), for example, or worse).
Since this is a pure function, which I want to use synchronously, ports were
also a very bad fit. Thankfully I eventually found “native modules”, and this
helpful guide. Native
modules are simply what the core Elm implementation and libraries themselves use
when they needs to access Javascript functionality (e.g. XMLHttpRequest
etc.). It was very easy to integrate my existing Javascript,
and there are no downsides – this was a very well tested pure function that had
years of use in production that convinced me it was correct and safe, and fast
enough.
Three hard problems, but three happy endings. (However, with the last one, there is a major caveat, which is the second half of this post).
Annoyances
The purpose of this section is to prepare you for things that may wear you down if you attempt an Elm project, so that you are fore-warned.
I am not a fan of writing HTML in Elm, but it works and the syntax is tolerable [2].
There were a few points where the type system let me down by not being powerful enough [3] [4] . There were some times where the static typing rules reject perfectly valid programs [5], which will annoy you if like me you are used to doing a lot of programming in dynamically typed languages.
Whichever way you look at it, there is often a lot of tedious boilerplate in Elm code – such as JSON decoders/encoders, enumerating all the messages your app sends and receives, wiring everything up in update functions.
The result is you do write a lot of code. At the point where my rewrite had approximate feature parity with the old version, I looked at the stats in terms of lines of code:
The old version:
approx 2000 line of TypeScript / Javascript
approx 230 lines of HTML
The new Elm version had:
approx 4000 lines of Elm
approx 230 lines of Javascript
A basic 20 line HTML page.
(blank lines excluded)
And both had some CSS/LESS, of very similar size.
Part of the reason for the large amount of Elm is that elm-format uses a lot of vertical space. Another reason would be that things like nested object updates in Elm are extremely verbose [6], and this also combines badly with the loss of context when handling a message, which is an annoyance in its own right [7].
I imagine that some of these may be improved a lot in future. Some could be solved with code generation (e.g. if you have a strongly-typed backend system generating JSON it could also generate Elm decoders, I think there may be packages that do this already for some languages), but some of them will only see limited improvements due to fundamental things in Elm's design. These are part of the cost of doing business in Elm.
Finally, there are certain types of bugs that I found happened more with Elm than with other languages, including a certain category of state bugs [8].
Elm's strengths
Despite the annoyances, however, Elm's type system in general is a tremendous asset. The record system is much more usable than Haskell's, which is good. When it comes to making changes and refactoring, Elm is so much nicer than most other languages I have used.
It does take a little while to adjust and get used to a slightly different flow. In Elm I generally make lots of very small changes, ensuring it compiles at each stage, because iteratively making lots of changes is easy and safe, while writing large bits of code that compiles first time is harder.
The result is wonderful confidence in making changes and knowing that you haven't broken anything. For a large part of the rewrite I did, I wrote no unit tests at all. I did have a set of previous integration tests for the previous incarnation of the page. Most of these applied to the new page with minimal changes, but I only bothered to actual use these very close to the end of the process. I was quite happy to make large changes and deploy them (to my beta testers) with only manual tests for the new things I had added.
Being able to avoid large numbers of tests was really freeing, and I probably gained much more here than I lost to the tedious boilerplate-y code I mentioned above [9].
A result of the Elm architecture is the time travelling debugger, which really is very cool. In fact, just being able to see the current state of the entire model is great.
The Elm architecture can also enable things you might not even attempt in other languages.
I wanted to have a “help tour” feature for this page, that takes the user through all the main UI elements (some of which are rather compressed or cryptic when you view them on a small screen, due to lack of captions, which was a deliberate choice to make room for other elements on the page). A help tour can also be useful for giving tips etc. on the way, and for welcoming new users.
There were a number of additional ideals and constraints. First, I wanted to use the user's current data as much as possible, rather than some random sample data. Second, I wanted the user to be able to re-run the tour at any point (and of course exit early). Third, to show certain parts of the UI, I'd need some fake data because otherwise certain things would be empty. As the tour progresses, this fake data changes. This means somehow keeping hold of the real data but viewing the fake data, and being able to make modifications to the fake data, without affecting the real model at all. Fourth, when in test mode, it's vital that most of the buttons don't work (otherwise you could end up triggering side-effectful code that could do an AJAX call, for example). However, certain side effects must happen – for example, if the user had triggered an AJAX call, then started the help tour, when the data comes in, it must be handled correctly, routed through the real model.
This sounded quite risky to get right. I wanted to be absolutely sure that I had done it correctly, so lots of special cases for “help tour mode” that I just had to remember to add would be a big no-no.
With the Elm architecture however, it turned out to be quite straightforward. You need to effectively have two copies of the model, which actually means you have an extra, optional one stored in the main one. (My first attempt gave me an error message about a recursive type, but it was a really nice error message, with a link to a page that explained exactly what I needed to do).
In the view code, you simply pass the fake model through when the help tour is enabled, plus info about the help tour controls, otherwise you pass the normal model.
The update function is a bit more complex. I implemented this using 3 update functions. The top level one either just dispatches to the 'normal update' or to the 'help tour update' function if the help tour is active. The 'help tour update' then has to make a decision about each message. Should it ignore it, pass it to the real model (using the 'normal update' function), pass it to the fake model, or to both? There were a few cases where it needed a bit of careful thought – e.g. window resize has to go to both models, and in some cases you might want to drop the side effects from one update but keep the model. However, since every message your app handles is enumerated into a single type, it is easy to be sure that you have handled every case.
This worked 99% perfectly the first time I tried it (that is, as soon as I had implemented the split 'update' function and got it to compile). The remaining 1% was entirely cosmetic and easily fixed. Further, adding this help tour required very few changes to other parts of the code – it was very well contained.
I simply wouldn't have attempted it, or possibly not even thought of it, if I hadn't been using the Elm architecture or something like it, or I would have quickly settled for much less in terms of how it should work.
However, even for this, there were parts of it that would have been really hard or tedious to implement in Elm (e.g. finding the location of a certain DOM element and then drawing an animated loop around it). These were straightforward to implement in Javascript with ports, so that's what I did.
The conclusion
I guess my biggest lesson from this is that Elm is really great at some things, and yet it complements, not replaces, other techniques and languages.
At the same time as doing the Elm re-implementation, I added some small functionality to another page on the site, using HTML in a template and JQuery. It was a button (in fact a set of buttons) with a simple API call. When the call completed successfully, the button was disabled and the caption changed to indicate success. As I was implementing it I was extremely relieved that I was not doing it in Elm, with all the overhead of enumerating messages, wiring everything up, JSON decoders etc. Elm is most verbose at the boundaries, and also most prone to failure at them (if you pass the wrong kind of JSON in, for example, there is not much Elm code can do). Since small bits of Elm code have a large boundary to volume ratio, the costs can very quickly outweigh the benefits.
If you have a small amount of very localised state to manage, or cases where the browser is already 90% there, Elm can be the Wrong Thing. For these cases, I no longer consider JQuery/VanillaJS to be a poor man's quick hack, it is a technically superior solution. Elm still has really basic bugs when it comes to simply getting a text input to work correctly. This is the result of re-implementing in Javascript what the browser can already do – you should avoid this if you can. Sometimes you don't need a framework.
But sometimes you do. The overall lesson is to not use Elm at all when it gives you little advantage, and when you do, be prepared to mix it with other languages.
The problem
The problem with this conclusion is that it seems that the Elm leadership and some of the community are really not on board with that mindset, but in fact quite the reverse.
I've seen the problem in a few ways. It's something I've mainly picked up as a vibe in comments I've read from lots of places, but it feels like there is a tendency to want to write everything in Elm, and attempt to solve every web development problem in Elm (e.g. elm-css instead of LESS, SCSS etc., style-elements).
I have nothing against these attempts, if that's what you want to do. But I've worried that there is an underlying attitude of “everyone else in web development is an idiot, just watch as we show everyone the way.”
That feeling came to a head a few days ago, and torpedoed the nice little conclusion to this blog post.
I found out that for the next version of Elm the compiler has been modified (or will be modified) to try to restrict the ability to use native modules (mentioned above) to a few core Elm organizations.
Elm has long had a very restrictive policy on what packages you can get from package.elm-lang.org, and that has included not allowing native modules as part of packages (apart from a certain whitelist).
But in the past few days there has been a change that is quite deliberately an attempt to impose that same restriction on everyone, application authors as well as library authors:
…in 0.19 only the elm-lang and elm-explorations organizations can compile and publish kernel code or effect managers. It will not be available in applications or other packages. [source]
('kernel code' is the new name for 'native code').
In that post, Evan expressed the belief that all existing Elm projects will be able to upgrade to the new version, and asked for feedback on specific problems, rather than on the principle of the decision.
This post is part of my answer. I'm answering on my blog, because I strongly dislike the way in which I've seen the terms of the discussion dictated in Elm community spaces, and dissenting voices shut down.
Before the specific problems comes a much bigger and more important issue of how mature the Elm community is and whether they are able to think objectively about Elm itself.
To aim to produce a radically different and safer client-side architecture for building web applications is ambitious. To achieve it is a great success. But to think “Elm will be so wonderful that no-one will ever want or need to write anything else” is hubris. And for anyone at this point in time to believe that Elm has already achieved that is madness.
While the arguments presented by Evan in the above posts and linked posts present a reasonable rationale for excluding native/kernel code for libraries that are available on package.elm-lang.org, they fall dreadfully short if we are talking about all Elm code everywhere.
There are two big reasons why the current policy is a terrible idea:
-
It assumes that the authors of Elm know better than everyone else.
Evan expressed the same attitude in this post. In response to the question “should I be writing native code”, his answer is an unqualified “No.”
The way I see it, this is a big problem. There is simply no way Evan can know your situation, your constraints, your problems. Yet he believes he knows what you should do better than you do.
I'm really an outsider to the community, but from some of the things I've read recently, the general level of disdain for Elm's users from Elm's leadership is quite astonishing, on a level I haven't seen elsewhere in the open source world [10].
-
It assumes that Elm is better than everything else.
Woven into all the posts I can find is the assumption that rewriting code in Elm is the right thing to do, and will make your code better etc. It ignores the possibility that you really might be able to write better code in other languages.
By closing the door to native modules, you are not only closing the door to Javascript, but all the other languages that compile to Javascript or can be accessed from it (such as WebAssembly).
Let's have a dose of reality. Elm is very far from perfect. And the Elm developers do not know your project better than you.
The reasons Elm needs an FFI of some kind, even if its an unstable one with no promise of backwards compatibility, are the same reasons every other mainstream language out there has an FFI – C allows you to embed assembly, Rust/C# have 'unsafe' code, Python has CFFI and CPython APIs etc. Mature languages, and languages designed by mature people, understand that sometimes the current language just does not cut it, and you need an escape hatch. Other languages often implement these with various levels of “use at own risk”. Often you will sacrifice portability (e.g. using CPython APIs or processor specific assembly code). Yet people take these risks and the ecosystem flourishes because of them (e.g. Numpy and Scipy which have caused Python to explode in popularity).
Take, for example, a function I mentioned above, which calculates the Damerau Levenshtein distance of two strings. If you research this, you'll find first a description of the algorithm in simple terms. (I implemented this in Elm, and the performance was laughably slow, totally unusable for my purposes). The second thing you'll find is a description of an optimised version of the algorithm, written in various languages or pseudo-code, but all of which assume mutable objects with destructive updates, which Elm does not have.
Since my project was a rewrite, I already had an implementation of this algorithm in Javascript which works great. I copied it from somewhere, don't know where now, but you can find very similar implementations in Java/C# etc.
There are lots of great reasons to not rewrite this in Elm:
It already works. If you don't understand that this is a good argument, you are a poor engineer.
After years of testing in production, I know it doesn't throw exceptions. In other words, it really does work.
It is a already pure function, taking two strings as input and returning an integer as output, so fits Elm architecture well. It does not need to have its API redesigned for Elm.
Rewriting might introduce bugs.
Since Elm is not well suited to this kind of code, rewriting might introduce performance regressions.
For goodness sake why are you still here, weren't points 1 to 5 enough?! I have a wife and two kids, several jobs, a dozen other ways I need to spend my time, I'm really not going to be responsible for my actions if you start suggesting that rewriting already working code in the current language-du-jour (which might be rather neat, but happens to makes it harder, not easier, to implement this specific code), is how I should be spending my evenings and weekends!
Seriously, though, point 5 is a bit stronger than “might". All the implementations you can find for the algorithm in question depend heavily on destructive updates, and I strongly suspect I would never be able to rewrite it with acceptable performance, even if I had many hours to burn, which I don't. And even if an acceptable Elm version could be written, if I discovered a problem like this in my first, small-ish Elm project, you can be absolutely sure there will be more algorithms like this out there. Making pure code run fast can be extremely hard [11].
In response to these kinds of problems, the current supported way to integrate Javascript in Elm is to use ports. Ports are often fine for side-effectful code that you do not trust. Compared to using Tasks (which compose in ways that ports do not), they can be very ugly. But without a shadow of a doubt they are very often hopelessly inadequate when it comes to pure code [12], and anyone who tells you differently is smoking something or a victim of Stockholm syndrome.
In the linked post, Evan assumes that if it possible to get rid of native modules from your project, then that will be an acceptable solution. It ignores the many reasons why people might not want to get rid of native code. These include:
The overall architecture of my app is much better if I have this native code implementing a pure function or Task, as opposed to using ports.
My current code has been thoroughly reviewed,
or was compiled to Javascript/WebAssembly from a much better language than Elm,
or has been subject to formal analysis techniques,
or has been war-hardened by years in production.
The Elm community seems to have fixated on the issue of being able to say “no runtime errors in Elm”. It seems to me this is just an instance of the elimination fallacy. There are plenty of things worse than a runtime exception – for example:
a runtime exception with insufficient context information to allow you to debug it (typical with Haskell, for example, and often with Elm).
silently buggy code, causing the wrong thing to be computed (and possibly saved permanently, corrupting data etc.)
code that cannot be easily written in your language, and so causes delays (and therefore costs money) or kills a project entirely. I nearly gave up on Elm for the second time and only persevered because I found there was a way to write native modules.
code that is correct, but whose performance is not adequate, but you don't realise until too late. A performance bug can be as bad as any other.
“It doesn't crash” is of course great, but at the end of the day is one of the least interesting things you can say about a program, and can be achieved by other means that writing in Elm. It would be a poor trade-off to sacrifice every other desirable quality for that one thing, especially when you have already achieved that one thing by other means.
From the Elm community I often see using Javascript being described as ‘unsafe’. However, this is a (probably unintentional) semantic bait-and-switch game. You can legitimately claim Elm is ‘safe’ and Javascript is ‘unsafe’ in an objective sense if you are talking about the specific property of type-safety. The problem is that the same word ‘unsafe’ is overloaded with the normal meaning of ‘risky’, and it is on this basis we are being warned away.
When you talk about risk, you have to think big picture. As well as the risks involved in rewriting I have already mentioned, the big one is the huge opportunity cost that comes with any rewrite. Very often the correct conclusion will be that rewriting a bit of code in Elm is the risky option. We need to stop playing this semantic game with ‘safe’ and ‘unsafe’.
When it comes to performance, you usually don't know yourself when you will hit a performance critical bit of code which might require more than Elm can give.
For example, on Elm Planet, I came across this post in which Ilias Van Peer attempts to optimise a toHex function. This was in response to a genuine need for an efficient version of this function. Let's assume that the person who asked for this was not an idiot, and really did need this (because assuming other developers are not idiots is always a good starting point).
Ilias managed to achieve a speedup of between 35-50%, which is admirable. I
wrote an implementation in native Javascript (hmm, does x => x.toString(16)
count as an implementation?). No prizes for guessing that this beats Ilias's 27
line optimised implementation by typically 33 times (3300%, as low as only 300%
for single digit input. I used the author's benchmark suite).
This 'Javascript' code is not “unsafe”. In fact the opposite is true – I am much
more confident that the browser authors managed to implement toString
correctly, and with good performance over a wide range of inputs, than for the
Elm versions.
But what will happen to your native module if the Elm kernel gets converted to WebAssembly? This apparently which might happen “someday” and is one of the rationales for stopping native modules. First, “someday” is vapourware. Even if it happened with a few years, that's still a really long time. And if/when it does:
WebAssembly can talk to Javascript and vice versa. There are some issues with this but it will probably be better by the time this is needed.
A lot of Javascript can be compiled to WebAssembly (and probably much more easily than you can rewrite it in Elm with the same performance). See AssemblyScript for example.
I will admit that a big part of my reluctance to use ports for my use cases comes down to pride – engineering pride in doing a good job.
Unnecessarily ugly, convoluted code (as produced by using ports for pure code) is something we want to avoid in programming, because it leads to bugs and both users and programmers being unhappy.
A sense of pride in your work and insisting on clean code and the best engineering solution is something that the Elm community should be keen to keep, not erode. Unfortunately, it seems that at present they have equated these things with “use only Elm”, which in some cases is just the Wrong Thing.
Hopefully the Elm leadership will mature and be able to see this. If not, removing the restrictions from the compiler should be an easy patch. I understand that talking of forking the compiler is seen as hostile, but when the compiler authors have gone out of their way to be hostile to users who have promoted Elm so far, this seems an entirely appropriate response.
For discussion of this post, see comments below and:
Footnotes