Before reading this, you might want to check it out in video form on Youtube, or with the embed below:
Video is probably a more helpful format for demonstrating the workflow I’m talking about. Otherwise read on. If you’re coming from the video to look at the Elisp code, it is found towards the bottom of this post.
“Recursive project search” is the name I’m giving to the flow where you do some kind of search to identify things that need to be done, but each of those tasks may leads you to do another search, etc. You need to complete all the sub-searches, but without losing your place in the parent searches.
This is extremely common in software development and maintenance, whether you are just trying to scope out a set of changes, or whether actually doing them. In fact just about any task can end being some form of this, and you never know when it will turn out that way.
This post is about how I use Emacs to do this, which is not rocket science but includes some tips and Elisp tweaks that can help a lot. When it comes to other editors or IDEs I’ve tried, I’ve never come close to finding a decent workflow for this, so I’ll have to leave it to other people to describe their approaches with other editors.
Example task - pyastgrep
I’m going to take as an example my pyastgrep project and a fairly simple refactoring I needed to do recently.
For background, pyastgrep is a command line program and library that allows you to grep Python code at the level of Abstract Syntax Trees rather than just string. At the heart of this is a function that takes a Python path, and converts it to AST and also XML.
The refactoring I want to do is make this function swappable, mostly so that users can apply different caching strategies to it. This is going to be a straightforward example of turning it into a parameter, or “dependency injection” if you want a fancy term. But that may involve modifying a number of functions in several layers of function calls.
The function in question is process_python_file.
Example workflow
The first step is a search, which in this case I will doing using lsp-mode. I happen to use lsp-pyright for Python, but there are other options.
So I’ll kick off by opening the file, putting my cursor on the function python_process_file, and calling M-x lsp-find-references. This returns a bunch of references. I can then step through them using M-x next-error and M-x previous-error — for which there are shortcuts defined, and I also do this so much that I have an F key for it — F2 and shift-F2 respectively.
Notice that in addition to the normal cursor, there is also a little triangle in the search results which shows the current result you are on.
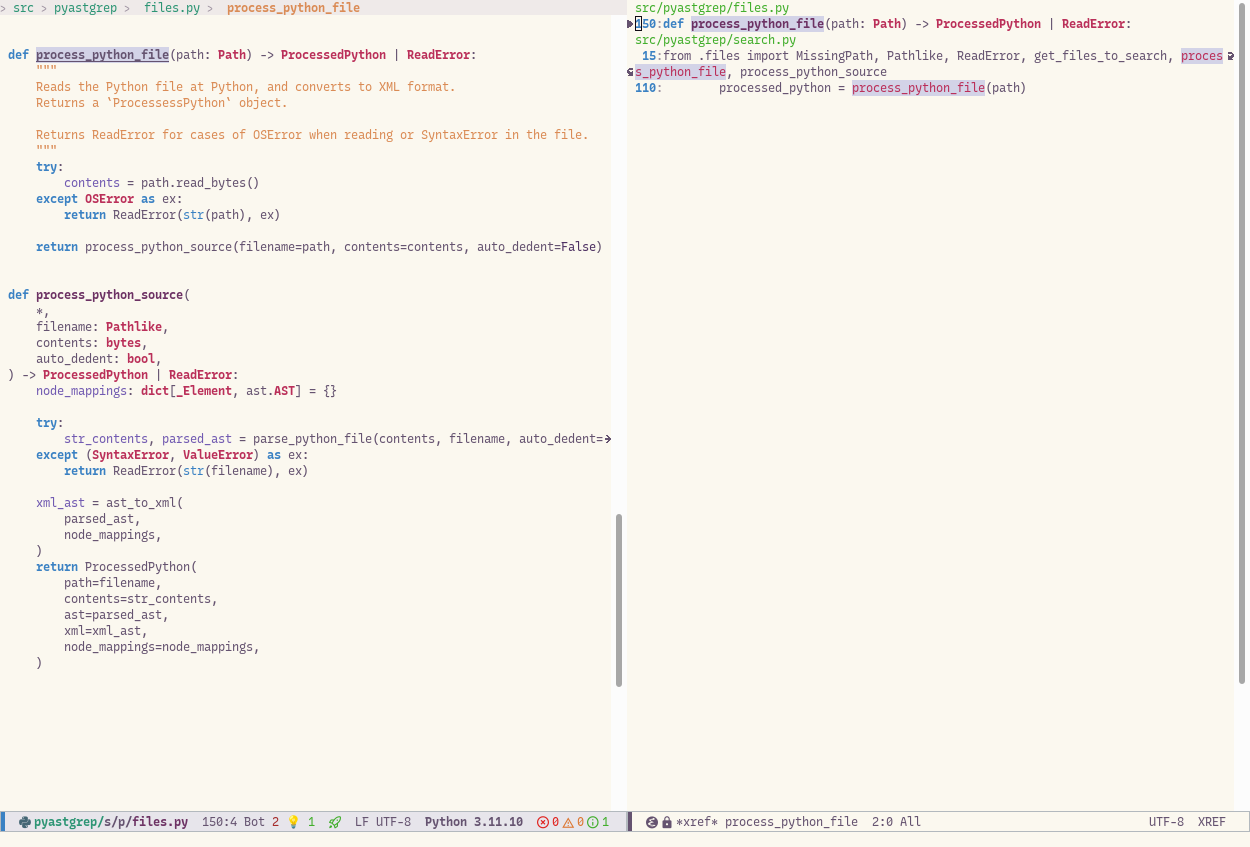
In this case, after the function definition itself, and an import, there is just one real usage – that last item in the search results.
The details of doing this refactoring aren’t that important, but I’ll include some of the steps for completeness. The last result brings me to code like this:
def search_python_file( path: Path | BinaryIO, query_func: XMLQueryFunc, expression: str, ) -> Iterable[Match | ReadError | NonElementReturned]: ... processed_python = process_python_file(path)
So I make process_python_file a parameter:
def search_python_file( path: Path | BinaryIO, query_func: XMLQueryFunc, expression: str, *, python_file_processor: Callable[[Path], ProcessedPython | ReadError] = process_python_file, ) -> Iterable[Match | ReadError | NonElementReturned]: ... processed_python = python_file_processor(path)
Having done this, I now need to search for all usages of the function I just modified, search_python_file, so that I can pass the new parameter — another M-x lsp-find-references. I won’t go into the details this time, in this case it involves the following:
Wherever search_python_file is used, either:
don’t pass
python_file_processor, because the default is what we want.or do pass it, usually by similarly adding a
python_file_processorparameter to the calling function, and passing that parameter intosearch_python_file.
This quickly gets me to search_python_files (note the s), and I find that it is imported in pyastgrep.api. There are no usages to be fixed here, but it is exported in __all__. This reminds me that the new parameter to this search_python_files function is actually intended to be a part of the publicly documented API — in fact this is the whole reason I’m doing this change. This means I now need to fix the docs. Another search is needed, but this time a string-based grep in the docs folder. For this, I use ripgrep and M-x rg-project-all-files.
So now I have another buffer of results to get through – I’m about 4 levels deep at this point.
Now comes one of the critical points in this workflow. I’ve completed the docs fix, and I’ve reached the end of that ripgrep buffer of search results:
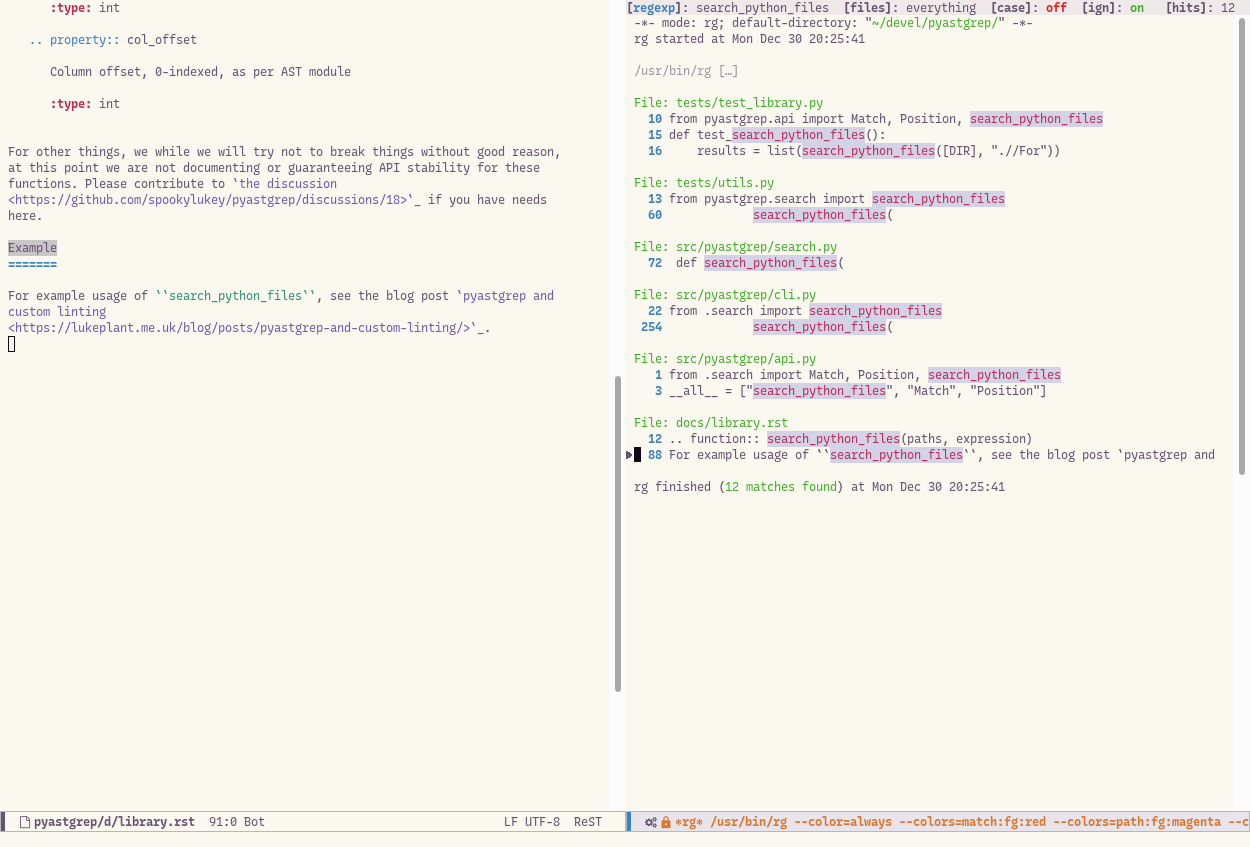
So I’ve come to a “leaf” of my search. But there were a whole load of other searches that I only got half way through. What happens now?
All I do is kill these finished buffers – both the file I’m done with, and the the search buffer. And that puts me back to the previous search buffer, at exactly the point I left off, with the cursor in the search buffer in the expected place.
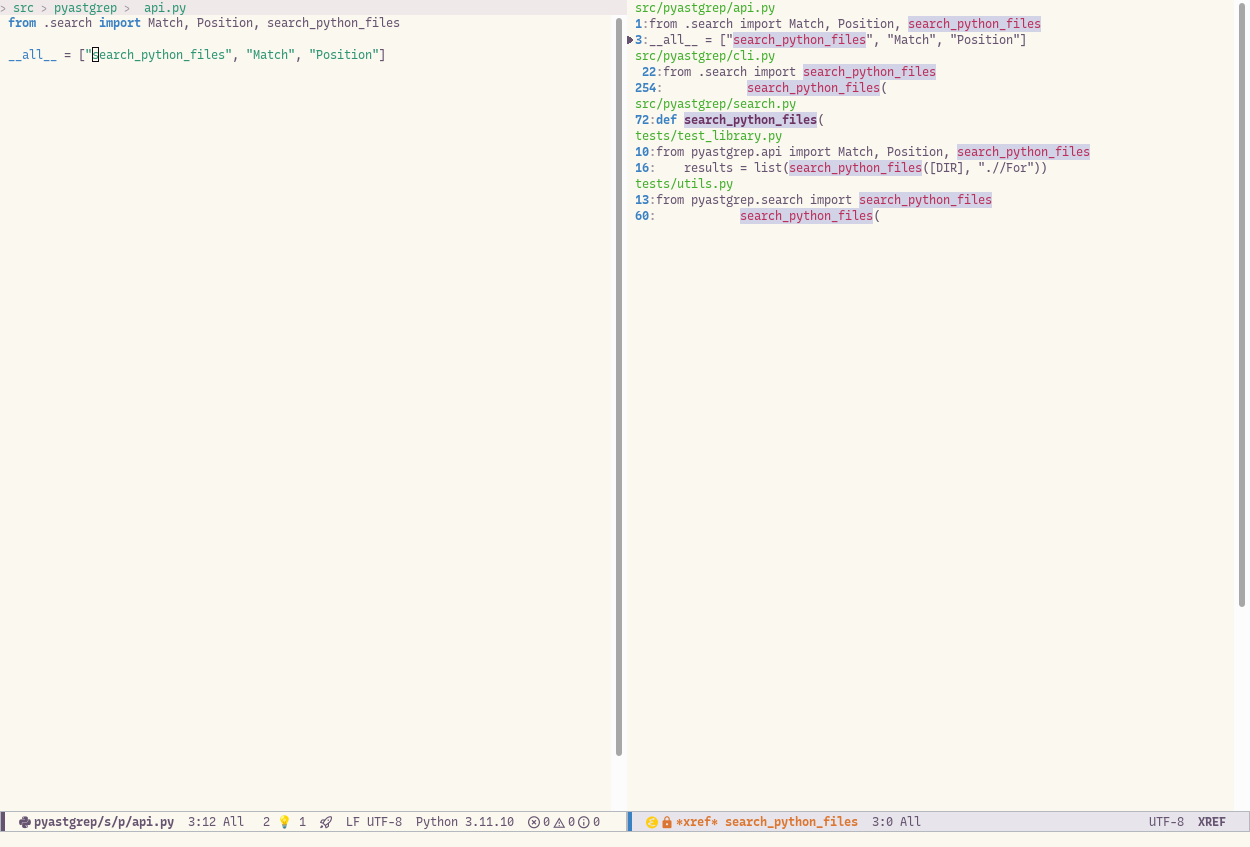
So I just continue. This process repeats itself, with any number of additional “side quests”, such as adding tests etc., until I get to the end of last search buffer, at which point I’m done.
Explanation
What I’ve basically done here is a depth-first recursive search over “everything that needs to be done to complete the task”. I started working on one thing, which lead to another and another, and for each one I went off and completed them as they came up.
Doing a search like that requires keeping track of a fair amount of state, and if I were doing that in my head, I would get lost very quickly and forget what I was doing. So what I do instead is to use Emacs buffers to maintain all of that state.
The buffers themselves form a stack, and each buffer has a cursor within it which tells me how far through the list of results I am. (This is equivalent to how recursive function calls typically work in a program - there will be a stack of function calls, each with local variables stored in a frame somehow).
In the above case I only went about 4 or 5 levels deep, and each level was fairly short. But you can go much deeper and not get lost, because the buffers are maintaining all the state you need. You can be 12 levels down, deep in the woods, and then just put it to one side and come back after lunch, or the next day, and just carry on, because the buffers are remembering everything for you, and the buffer that is in front of you tells you what you were doing last.
It doesn’t even matter if you switch between buffers and get them a bit out of order – you just have to ensure that you get to the bottom of each one.
Another important feature is that you can use different kinds of search, and
mix and match them as you need, such as lsp-find-references and the ripgrep
searches above. In addition to these two, you can insert other
“search-like” things, like linters, static type checkers, compilers and build
processes – anything that will return a list of items to check. So this is not a
feature of just one mode, it’s a feature of how buffers work together.
At each step, you can also apply different kinds of fixes – e.g. instead of manually editing, you might be using M-x lsp-rename on each instance, and you might be using keyboard macros etc.
When I’ve attempted to use editors other than Emacs, this is one of the things I’ve missed most of all. Just getting them to do the most basic requirement of “do a search, without overwriting the previous search results” has been a headache or impossible – although I may have given up too soon.
I’m guessing people manage somehow – or perhaps not: I’ve sometimes noticed that I’ve been happy to take on tasks that involved this kind of workflow which appeared to be daunting to other people, and completed them without problem, which was apparently impressive to others. I also wonder whether difficulties in using search in an editor drive a reluctance to take on basic refactoring tasks, such as manual renames, or an inability to complete them correctly. If so, it would help to explain why codebases often have many basic problems (like bad names).
In any case, I don’t think I can take for granted that people can do this, so that’s why I’m bothering to post about it!
Requirements
What do you need in Emacs for this to work? Or what equivalent functionality is needed if you want to reproduce this elsewhere?
First, the search buffer must have the ability to remember your position. All the search modes I’ve seen in Emacs do this.
Second, you need an easy way to step through results, and this is provided by the really convenient
M-x next-errorfunction which does exactly what you want (see the Emacs docs for it, which describe how it works). This function is part of Compilation Mode or Compilation Minor Mode, and all the search modes I’ve seen use this correctly.Thirdly, the search modes mustn’t re-use buffers for different searches, otherwise you’ll clobber earlier search results that you hadn’t finished processing. Some modes do this automatically, others have a habit of re-using buffers — but we can fix that:
Unique buffers for searches
If search commands re-use search buffers by default, I’ve found it’s usually pretty easy to override the behaviour so that you automatically always get a unique buffer for each new search you do.
The approach you need often varies slightly for each mode, but the basic principle is similar - different searches should get different buffer names, and you can use some Elisp Advice to insert the behaviour you want.
So here are the main ones that I override:
rg.el for ripgrep searching:
This is just using the save feature built in to rg.el.
This goes in your init.el. Since I use use-package I usually put it inside the relevant (use-package :config) block.
For lsp-find-references I use the following which makes a unique buffer name based on the symbol being searched for:
(advice-add 'lsp-find-references :around #'my/lsp-find-references-unique-buffer) (defun my/lsp-find-references-unique-buffer (orig-func &rest args) "Gives lsp-find-references a unique buffer name, to help with recursive search." (let ((xref-buffer-name (format "%s %s" xref-buffer-name (symbol-at-point)))) (apply orig-func args)))
Then for general M-x compile or projectile-compile-project commands I use the following, which gives a unique buffer name based on the compilation command used:
(advice-add 'compilation-start :around #'my/compilation-unique-buffer) (defun my/compilation-unique-buffer (orig-func &rest args) "Give compilation buffers a unique name so that new compilations get new buffers. This helps with recursive search. If a compile command is run starting from the compilation buffer, the buffer will be re-used, but if it is started from a different buffer a new compilation buffer will be created." (let* ((command (car args)) (compilation-buffer (apply orig-func args)) (new-buffer-name (concat (buffer-name compilation-buffer) " " command))) (with-current-buffer compilation-buffer (rename-buffer new-buffer-name t))))
I use this mode quite a lot via M-x compile or M-x
projectile-compile-project to do things other than compilation – for custom
search commands, like pyastgrep, for linters and static
checkers.
Other tips
External tools
Many of externals tools that you might run via M-x compile already have output that is in exactly the format that Emacs compilation-mode expects, so that search results or error messages become hyperlinked as expected inside Emacs. For example, mypy has the right format by default, and most older compilers like gcc etc.
For those tools that don’t, sometimes you can tweak the options of how they print. For example, if you run ripgrep as rg --no-heading (just using normal M-x compile, without a dedicated ripgrep mode), it produces the necessary format.
Alternatively, you can make custom wrappers that fix the format. For example, I’ve got this one-liner bash script to wrap pyright:
Buffer order and keeping things tidy
Emacs typically manages your buffers as a stack. However, it’s very easy for things to get out of order as you are jumping around files or search buffers. It doesn’t matter too much if you go through the search buffers in the “wrong” order – as long as you get to the bottom of all of them. But to be sure I have got to the bottom, I do two things:
Before starting anything that I anticipate will be more than a few levels deep, I tidy up by closing all buffers but the one I’m working on. You can do this with
crux-kill-other-buffersfrom crux. I have my own version that is more customised for my needs —crux-kill-other-buffersonly kills buffers that are files.At the end, when I think I’m done, I check the buffer list (
C-x C-b) for anything else I missed.
Project context
In order to limit the scope of searches to my project, I’m typically leaning on projectile.el, but there are other options.
Conclusion
I hope this post has been helpful, and if you’ve got additional tips for this kind of workflow, please leave a comment!