In Hillel Wayne’s post “I am disappointed by dynamic typing”, he expresses his sense that the Python ecosystem doesn’t really make the most of the possibilities that Python provides as a dynamically typed language. This is an important subject, since every Python program pays a very substantial set of costs for Python’s highly dynamic nature, such as poor run-time performance, and maintainability issues. Are we we getting anything out of this tradeoff?
I think Hillel makes some fair points, and this post is intended as a response rather than a rebuttal. Recently there has been a significant influence of static type systems which I think might be harmful. The static type system we have in the form of mypy/pyright (which is partly codified in PEP 484 and following) seems to be much too heavily inspired by what is possible to map to other languages, rather than the features that Python provides.
(As a simple example to support that claim, consider the fact that Python has had support for keyword arguments since as long as I can remember, and for keyword-only arguments since Python 3.0. But typing.Callable has zero support for them, meaning they can’t be typed in a higher-order context. . This is bad, since they are a key part of Python’s excellent reputation for readability, and we want more keyword-only arguments, not fewer.
[EDIT: it looks like there is another way to do it, it’s just about 10 times more work, so the point kind of stands.]
I can give more examples, but that will have to wait for another blog post).
I’m worried that a de-facto move away from dynamic stuff in the Python ecosystem, possibly motivated by those who use Python only because they have to, and just want to make it more like the C# or Java they are comfortable with, could leave us with the very worst of all worlds.
However, I also think there are plenty of counter-examples to Hillel’s claim, and that’s what this post will explore.
Hillel was specifically thinking about, in his own words:
“runtime program manipulation”
“programs that take programs and output other programs”
“thinking of the whole runtime environment in the same way, where everything is a runtime construct”
…and he gave some examples that included things like:
run-time type modification
introspection/manipulation of the stack
passing very differently typed objects through normal code to collect information about it.
I’m going to give lots of examples of this kind of thing in Python, and they will all be real world examples. This means that either I have used them myself to solve real problems, or I’m aware that other people are using them in significant numbers.
Before I get going, there are some things to point out.
First, I don’t have the exact examples Hillel is looking for – but that’s because the kind of problems I’ve needed to solve have not been exactly the same as his. My examples are all necessarily limited in scope: since Python allows unrestricted side-effects in any function, including IO and being able to modify other code, there are obviously limits into how well these techniques can work across large amounts of code.
I do think, however, that my examples are in the same general region, and some of them very close. On both sides we’ve got to avoid semantic hair-splitting – you can argue that every time you use the class keyword in Python you are doing “run-time type creation”, rather than “compile-time type creation”, because that’s how Python’s classes work. But that’s not what Hillel meant.
Second, many of these more magical techniques involve what is called monkey patching. People are often confused about the difference between monkey patching and “dynamic meta-programming”, so I’ve prepared a handy flow chart for you:
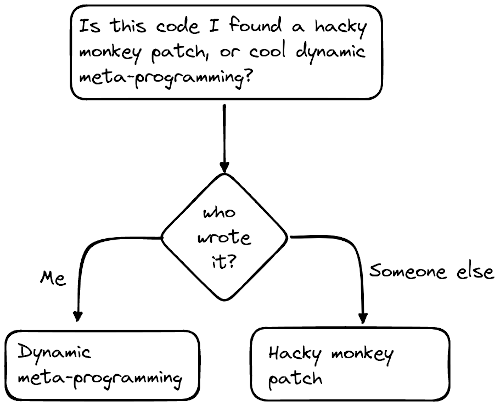
There are, however, many instances of advanced, dynamic techniques that never get to the point of the chart above, and that’s because you never know about them. What you know is that the code does something useful, and it does so reliably enough that you don’t need to know what techniques contributed to it. And this is, I think, the biggest problem in what Hillel is asking for. The best examples of these techniques will be reliable enough that they don’t draw attention to themselves, and you immediately take them for granted.
Which is also to say that you cannot discount something I mention below just because it is so widely used that you, too, have taken it for granted – that would effectively be saying that the only examples that count are the ones that have proved to be so wild and wacky that everyone has decided they are a bad idea.
Third, you might also discount these examples as “just using features the language provides”, rather than “hyper-programming” or something exotic. On the one hand, it would be true, but also unfair in the context of this debate. The most obvious example is eval. This is clearly a very powerful technique not available to many statically typed languages, and exactly the kind that Hillel is looking for – you are literally creating more of your program as your program is running. On the other hand, it’s nothing more than a builtin function.
Finally, a number of these examples don’t involve “production” code i.e. the code is typically run only on developer machines or in CI. These still count, however – just like many of Hillel’s examples are in the area of testing. The reasons they still count are 1) developers are humans too, and solving their problems is still important and 2) the techniques used by developers on their own machines are useful in creating high quality code for running on other people’s machines, where we don’t want to incur the performance or robustness penalties of the techniques used.
So, here are my examples. The majority are not my own code, but I’ve also taken the opportunity to do some fairly obvious bragging about cool things I’ve done in Python.
Gooey
Gooey is a library that will re-interpret argparse entry points as if they were specifying a GUI. In other words, you do “import gooey”, add a decorator and it transforms your CLI program into a GUI program. Apparently it does this by re-parsing your entry point module, for reasons I don’t know and don’t need to know. I do know that it works for programs I’ve tried it with, when I wanted to make something that I was using as a CLI, but also needed to be usable by other family members. A pretty cool tool that solves real problems.
Werkzeug’s interactive debugger
Werkzeug provide a debugger middleware which works with any WSGI-compliant Python web framework (which is most of them) with the following extremely useful behaviour:
Crashing errors are automatically intercepted and an error page is shown with a stack trace instead of a generic 500 error.
For any and every frame of the stack trace, you can, right from your web browser, start a Python REPL at that frame – i.e. you can effectively continue execution of the crashed program at any point in the stack, or from multiple points simultaneously.
This is extremely useful, to say the least.
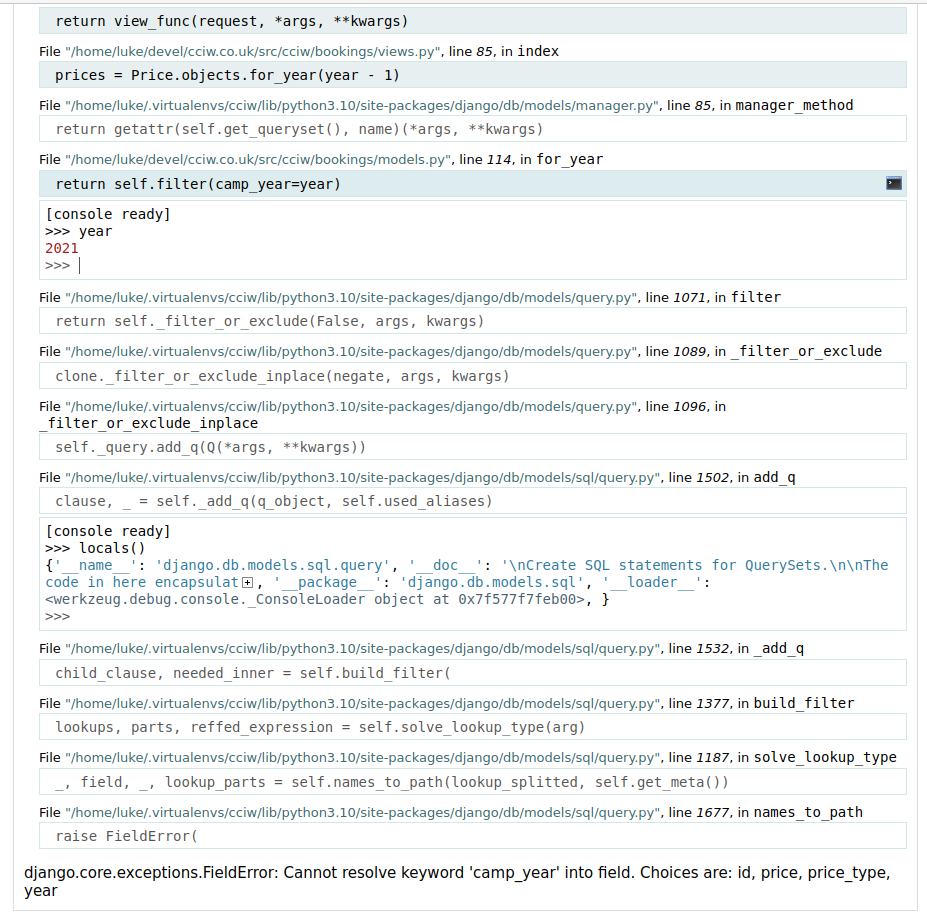
(For Django users – you can use this most easily using django-extensions)
Hybrid attributes in SQLAlchemy
I’m sure there are many examples of advanced dynamic techniques in SQLAlchemy, and I’m not the best qualified to talk about them, but here is a cool one I came across that helps explain the kind of thing you can do in Python.
Suppose you have an ORM object with some attributes that come straight from the database, along with some calculated properties. In the example below we’ve got a model representing an account that might have payments against it:
class Account(Base): # DB columns: amount_paid: Mapped[Decimal] total_purchased: Mapped[Decimal] # Calculated properties: @property def balance_due(self) -> Decimal: return self.total_purchased - self.amount_paid @property def has_payment_outstanding(self) -> bool: return self.balance_due > 0
Very often you find yourself in a situation like this:
Sometimes you have already loaded an object from the DB, and want to know a calculated value like “does this account have an outstanding payment?”. This shouldn’t execute any more database queries, since you’ve already loaded everything you need to answer that question.
But sometimes, you want to re-use this logic to do something like “get me all the accounts that have outstanding payments”, and it is vital for efficiency that we do the filtering in the database as a SQL
WHEREclause, rather than loading all the records into a Python process and filtering there.
How could we do this in SQLAlchemy without duplicating the logic regarding balance_due and has_outstanding_payment?
The answer is hybrid attributes:
from sqlalchemy.ext.hybrid import hybrid_propertyreplace
propertywithhybrid_propertyon the two properties.
That is all. Then you can do:
This will generate a SQL query that looks like this:
SELECT account.id, account.amount_paid, account.total_purchased FROM account WHERE (account.total_purchased - account.amount_paid > 0) = 1
What’s going on here? If you have a normal model instance an_account, retrieved from a database query, and you do an_account.has_payment_outstanding, then in the has_payment_outstanding function body above, everything is normal: self is bound to an_account, attributes like total_purchased will be Decimal objects that have been loaded from the database.
However, if you use Account.has_payment_outstanding, the self variable gets bound to a different type of object (the Account class or some proxy), and so things like self.total_purchased instead resolve to objects representing columns/fields. These classes have appropriate “dunder” methods defined, (__add__, __gt__ etc) so that operations done on them, such as maths and comparisons, instead of returning values immediately, return new expression objects that track what operations were done. These can then be compiled to SQL later on. So we can execute the filtering as a WHERE clause in the DB.
The point here is: we are passing both “normal” and “instrumented” types through the same code in order to completely change our execution strategy. This allows us to effectively compile our Python code into SQL on the fly. This is essentially identical to Hillel’s example of passing instrumented objects (“Replacer” class) through normal code to extract certain information about what operations were done.
This is a very neat feature in SQLAlchemy that I’m rather jealous of as a Django user. If you want the same efficiency in Django, you have to define the instance properties and the database filtering separately, and usually physically not next to each other in the code. The closest we have is Query expressions but they don’t work quite the same.
Pony ORM
This ORM has a way of writing SQL select queries that appears even more magical. Using an example from their home page, you write code like this:
The result of this is a SQL query that looks like this:
SELECT "c"."id" FROM "customer" "c" LEFT JOIN "order" "order-1" ON "c"."id" = "order-1"."customer" GROUP BY "c"."id" HAVING coalesce(SUM("order-1"."total_price"), 0) > 1000
A normal understanding of generator expressions suggests that the select function is consuming a generator. But that couldn’t explain the behaviour here. Instead, it actually introspects the frame object of the calling code, then decompiles the byte code of the generator expression object it finds, and builds a Query based on the AST objects.
PonyORM doesn’t advertise all that, of course. It advertises a “beautiful” syntax for writing ORM code, because that’s what matters.
Django
This is the web framework I know well, as I used to contribute significantly, and I’ll pick just a few important examples from the ORM, and then from the broader ecosystem.
ForeignKey
Suppose, to pick one example of many, you are writing django-otp, a third party library that provides a One Time Password implementation for 2FA requirements. You want to create a table of TOTP devices that are linked to user accounts, and so you have something like this:
Later on, you have code that starts with a User object and retrieves their TOTP devices, and it looks something like this:
This is interesting, because my user variable is an instance of a User model that was provided by core Django, which has no knowledge of the third party project that provides the TOTPDevice model.
In fact it goes further: I may not be using Django’s User at all, but my own custom User class, and the TOTPDevice model can easily support that too just by doing this:
This means that my User model has no knowledge of the TOTPDevice class, nor the other way around, yet instances of these classes both get wired up to refer to each other.
What is actually going on to enable this?
When you import Django and call setup(), it imports all the apps in your
project. When it comes to the TOTPDevice class, it sees the "auth.User"
reference and finds the class it refers to. It then modifies that
class, adding a totp_devices descriptor object to the class attributes.
This is run-time type modification.
The result is that when you do user.totp_devices, you get a Manager instance that does queries against the TOTPDevice table. It is a specific kind of manager, known as a RelatedManager, with the special property that it automatically does the correct filter() calls to limit returned values to those related to the model instance, among other things.
ManyToMany models
One common need in database applications is to have many-to-many relationships between two models. Typically this can be modelled with a separate table that has foreign keys to the two related tables.
To make this easy, Django provides a ManyToManyField. For simple cases, it’s
tedious to have to create a model for the intermediate table yourself, so of
course Django just creates it for you
if you don’t provide your own, using type() with 3 arguments. This is again run-time type creation.
Consequences
These examples of run-time type modification or creation are perhaps not the most extreme or mind-bending. But they are something even better: useful. It’s these features, and things like them, that enable an ecosystem of third party Django libraries that can integrate with your own code without any problems.
Python also always gives us enough flexibility to have a good backwards compatibility story – so that, for example, the swappable User model was introduced with an absolute minimum of fuss for both projects and pluggable Django apps.
I’m interested in functional programming, Haskell in particular – this blog even ran on Haskell for a time – so I always take interest in developments in the Haskell web framework world. I see lots of cool things, but it always seems that the ecosystems around Haskell web frameworks are at least 10 years behind Django. One key issue is that in contrast to Django or other Python frameworks, Haskell web frameworks almost always have some kind of code generation layer. This can be made to work well for the purposes envisaged by the framework authors, but it never seems to enable the ecosystem of external packages that highly dynamic typing supports.
Please note that I’m not claiming here that Python is better than Haskell or anything so grand. I’m simply claiming that Python does enable very useful things to be built, and those things are made possible and easy because of Python’s design, rather than despite it.
I think this is important to say. Python has become massively more popular than it was when I first started to use it, and there are increasing numbers of people who use it only because of network effects, and don’t understand why it got so popular in the first place. These people can sometimes assume that it’s fundamentally a poorly designed language that we are just lumped with – today’s PHP – whose best trajectory is to make it more like Java or C# or Rust etc. I think that would be a big mistake.
Baserow
One project that takes Python’s run-time type creation further is Baserow. In their case, their customers create database applications, and the metadata for those tables is stored in … tables. They like Django and want to use it as much as possible. But they also want their customers’ actual data tables to be normal RDBMS tables, and therefore benefit from all the typical RDBMS features to make their tables fast and compact etc. (I’ve seen and worked on systems that took the opposite approach, where customer schema was relegated to second class storage – essentially a key-value table – and the performance was predictably awful).
And they want plug-in authors to be able to use Django too! Some people are just greedy! They have a nice article describing how they achieved all this: in short, they use type() for run-time type creation and then leverage everything Django gives them.
This has the interesting effect that the metadata tables, along with their own business tables, live at the same level as their customers’ tables which are described by those metadata tables. This “meta and non-meta living at the same level” is a neat illustration of what Python’s type system gives you:
When you first discover the mind-bending relationships around type(type) == type, you might think of an infinitely-recursive relationship. But actually, an infinite relationship has been flattened to being just 3 layers deep – instance, class, metaclass. The last layer just recurses onto itself. The infinity has been tamed, and brought into the same structures that you can already deal with, and without changing language or switching to code generation techniques. This is one reason why many examples of the “hyper-programming” that Hillel talks about can just be dismissed as normal programming – but they are simply hyper-programming that you are now taking for granted.
CCiW data retention policy
CCiW is a small charity I’ve been involved with for a long time. When I came to implement its GDPR and data retention policies, I found another example of how useful it is having access to Django’s meta-layer (generic framework code) on the same level as my normal data layer (business specific classes and tables), in ways that often aren’t the case for statically typed languages that resort to code-generation techniques for some of these things.
I wanted to have a data retention policy that was both human readable and machine readable, so that:
We don’t have keep two separate documents in sync.
the CCiW committee and other interested parties would be able to read the policy that actually gets applied, rather than merely what the policy was supposed to be.
I could have machine level checking of the exhaustiveness of the policy.
My solution was to split the data retention policy into two parts:
a heavily commented, human-and-machine readable Literate YAML file with a nicely formatted version, that I can genuinely claim is our data retention policy, and that it is automatically applied,
and a Python implementation that reads this file and applies it, along with some additional logic.
A key part of the neatness of this solution is that the generic, higher level code (which reads in a YAML file, and therefore has to treat field names and table names as strings), and the business/domain specific logic can sit right next to each other. The end result is something that’s both efficient and elegant, with great separation of concerns, and virtually self-maintaining – it complains at me automatically if I fail to update it when adding new fields or tables.
In terms of performance, the daily application for the data retention policy for the entire database requires, at the moment, just 5 UPDATE and 3 DELETE queries, run once a day. This is made possible by:
using the power of an ORM,
using generic code to build up
**kwargsto pass to QuerySet.update(),seamlessly integrating these two with business specific logic.
Here is one of the queries the ORM generates, which is complex enough that I wouldn’t attempt to write this by hand, but it correctly applies business logic like not erasing any data of people who still owe us money, and combines all the erasure that needs to be done into a single query.
Query tracing
A common need in database web applications is development tools that monitor what database queries your code is generating and where they are coming from in the code. In Python this is made very easy thanks to sys._getframe which gives you frame objects of the currently running program.
For Django, the go-to tool that uses this is django-debug-toolbar, which does an excellent job of pinpointing where queries are coming from.
There have been times when it has failed me, however. In particular, when you are working with generic code, such as the Django admin or Django REST framework, in which the fields and properties that will be fetched may be defined as strings in declarative code, a stack trace alone is not enough to work out what is triggering the queries. For example, you might have an admin class defined like this:
And the stack trace points you to this code:
for field_index, field_name in enumerate(cl.list_display): f, attr, value = lookup_field(field_name, result, cl.model_admin)
It’s correct, but not helpful. I need to know what the value of the local variable field_name is in that loop to work out what is actually causing these queries.
In addition, in one case I was actually working with DRF endpoints, not the HTML endpoints the debug toolbar is designed for.
So, I wrote my own utilities that, in addition to extracting the stack, would also include certain local variables for specified functions/methods. I then needed to add some aggregation functionality and pretty-printing for the SQL queries too. Also, I wrote a version of assertNumQueries that used this better reporting.
This was highly effective, and enabled me and members of my team to tackle these DRF endpoints that had got entirely out of hand, often taking them from 10,000+ database queries (!) to 10 or 20.
This is relatively advanced stuff, but not actually all that hard, and it’s within reach of many developers. It doesn’t require learning a whole new language or deep black magic. You can call sys._getframe interactively from a REPL and find out what it does. The biggest hurdle is actually making the mental leap that says “I need to build this, and with Python, I probably can”.
time-machine and pyfakefs
As an example of “entire program transformation”, time-machine is an extremely useful library that mocks out date/time functions across your entire program, and pyfakefs is one that does the same thing for file-system calls.
These contrast with libraries like unittest.mock do that do monkey patching on a more limited, module-by-module basis.
This technique is primarily useful in automated test suites, but it has a profound impact on the rest of your code base. In other languages, if you want to mock out “all date/time access” or “all filesystem access”, you may end up with a lot of tedious and noisy code to pass these dependencies through layers of code, or complex automatic dependency injection frameworks to avoid that. In Python, those things are rarely necessary, precisely because of things like time-machine and pyfakefs – that is, because your entire program can be manipulated at run-time. Your code base then has the massive benefit of a direct and simple style.
Environment detection
My current employer is Datapane who make tools for data apps. Many of our customers use Jupyter or similar environments. To make things work really smoothly, our library codes detects the environment it is running in and responds, and in some cases interacts with this environment (courtesy of Shahin, our Jupyter guy). This is an application of Python’s great support for introspection of the running program. There are a bunch of ways you can do this kind of thing:
checking the system environment in
os.environchecking the contents of
sys.modulesusing
sys._getframeto examine how you are being called.attempting to use get_ipython and seeing if it works etc.
This is an example of the “whole runtime environment” being dynamic and introspectable, and Jupyter Notebook and its huge ecosystem make great use of this.
With some of the bigger features we’re working on at the moment at Datapane, we’re needing more advanced ways of adjusting to the running environment. Of course, as long it works, none of the implementation matters to our customers, so we don’t advertise any of that. Our marketing tagline for this is “Jupyter notebook to a shareable data app in 10 seconds”, not “we’re in your Python process, looking at your sys.modules”.
After doing a grep through my site-packages, I found that doing sys._getframe for different kinds of environment detection is relatively common – often used for things like “raise a deprecation warning, but not if we are being called from these specific callees, like our own code”. Here’s just one more example:
boltons provides a make_sentinel function. The docs state that if you want “pickleability”, the sentinel must be stored in a module-level constant. But the implementation goes further and checks you are doing that using a sys._getframe trick. This is just a simple usability enhancement in which code checks that it is being used correctly, made possible by Python’s deep introspection support, but this kind of thing adds up. You will find many similar things in small amounts scattered across different libraries.
fluent-compiler
Fluent is a localisation system by Mozilla. I wrote and contributed the initial version of the official fluent.runtime Python implementation, which is an interpreter for the Fluent language, and I also wrote a second implementation, fluent-compiler.
Of all the libraries I’ve written, this was the one I enjoyed most, and it’s also the least popular it seems – not surprising, since GNU gettext provides a great 90% solution, which is enough for just about everyone, apart from Mozilla and, for some reason I can’t quite remember, me. However, I do know that Mozilla are actually using my second implementation in some of their web projects, via django-ftl, and I’m using it, and it has a few GitHub stars, so that counts as real world!
Here are some of the Hillel-worthy Python techniques I used:
Compile-to-Python
In fluent-compiler, the implementation strategy I took was to compile the parsed Fluent AST to Python code, and exec it. I actually use Python AST nodes rather than strings, for various security reasons, but this is basically the same as doing eval, and that same technique is used by various other projects like Jinja and Mako.
If anything qualifies as “programs that create programs on the fly”, then using exec, eval or compile must do so! The main advantage of this technique here is speed. It works particularly well with Fluent, because with a bit of static analysis, we can often completely eliminate the overhead that would otherwise be caused by its more advanced features, like terms and parameterized terms, so that at run-time they cost us nothing.
This works even better when combined with PyPy. For the simple and common cases, under CPython 3.11 my benchmarks show a solution using fluent-compiler is about 15% faster than GNU gettext, while under PyPy it’s more than twice as fast. You should take these numbers with a pinch of salt, but I am confident that the result is not slow, despite having far more advanced capabilities than GNU gettext, which is not true for the first implementation – the compiler is about 5-10x faster than the interpreter for common cases on CPython.
Additionally, there are some neat tricks you can do when implementing a compiler using the same language that you are compiling to, like evaluating some things ahead of time that you know are constants.
Dynamic test methods
While developing the second implementation, I used the first implementation as a reference. I didn’t want to duplicate every test, or really do anything manually to every test, I just wanted a large sub-set of the test suite to automatically test both implementations. I also wanted failures to clearly indicate which implementation had failed, i.e. I wanted them to run as separate test cases, because the reference implementation could potentially be at fault in some corner cases.
As I was using unittest, my solution was this: I added a class decorator that modified the test classes by removing every method that started with test_, replacing it with two methods, one for each implementation.
This provided almost exactly the same functionality as one of Hillel’s wished-for examples:
Add an output assertion to an optimized function in dev/testing, checking that on all invocations it matches the result of an unoptimized function
I just used a slightly different technique that better suited my needs, but also made great use of run-time program manipulation.
morph_into
As part of the Fluent-to-Python compilation process, I have a tree of AST objects that I want to simplify. Simplifications include things like replacing a “string join” operation that has just one string, with that single string – so we need completely different types of objects. Even in a language that has mutation this can be a bit of a pain, because we’ve got to update the parent object and tell it to replace this child with a different child, and there are many different types of parent object with very different shapes. So my solution was morph_into:
def morph_into(item, new_item): """ Change `item` into `new_item` without changing its identity """ item.__class__ = new_item.__class__ item.__dict__ = new_item.__dict__
With this solution, we leave the identity of the object the same, so none of the pointers to it need to be updated. But its type and all associated data is changed into something else, so that, other than id(), the behaviour of item will now be indistinguishable from new_item. Not many languages allow you to do this!
I spent quite a lot of time wondering if I should be ashamed or proud of this code. But it turned out there was nothing to be ashamed of – it saved me writing a bunch of code and has had really no downsides.
Now, this technique won’t work for some things, like builtin primitives, so it can’t be completely generalised. But it doesn’t need that in order to be useful – all the objects I want to do this on are my own custom AST classes that share an interface, so it works and is “type safe” in its own way.
I’m far from the first person to discover this kind of trick when implementing compilers. In this comparison of several groups of people working on a compiler project, one of the most impressive results came from a single-person team who chose Python. She used way less code, and implemented way more features than the other groups, who all had multiple people on their teams and were using C++/Rust/Haskell etc. Fancy metaprogramming and dynamic typing were a big part of the difference, and by the sounds of it she used exactly the same kinds of things I used:
Another example of the power of metaprogramming and dynamic typing is that we have a 400 line file called
visit.rsthat is mostly repetitive boilerplate code implementing a visitor on a bunch of AST structures. In Python this could be a short ~10 line function that recursively introspects on the fields of the AST node and visits them (using the__dict__attribute).
Again, I’m not claiming “dynamic typing is better than static typing” – I don’t think it’s even meaningful to do that comparison. I’m claiming that highly dynamic meta-programming tricks are indeed a significant part of real Python code, and really do make a big difference.
Pytest
Pytest does quite a few dynamic tricks. Hillel wishes that pytests functionality was more easily usable elsewhere, such as from a REPL. I’ve no doubt this is a legitimate complaint – as it happens, my own use cases involve sticking a REPL in my test, rather than sticking a pytest in my REPL. However, you can’t claim that pytest isn’t a valid example, or isn’t making use of Python’s dynamism – it does, and it provides a lot of useful functionality as a result, including:
Assert rewriting
The most obvious is perhaps their assert rewriting, which relies on modifying the AST of test modules to inject sub-expression information for when asserts fail. It makes test assertions often much more immediately useful.
Automatic dependency injection of fixtures
Pytest provides one of the few cases of automatic dependency injection in Python where I’ve thought it was a good idea. It also makes use of Python’s dynamism to make this dependency injection extremely low ceremony. All you need to do is add a parameter to your test function, giving the parameter the name of the fixture you want, and pytest will find that fixture in its registry and pass it to your function.
Others
This post is way too long already, and I’ve done very little actual searching for this stuff – almost all my examples are things that I’ve heard about in the past or done myself, so there must be far more than these in the real world out there. Here are a bunch more I thought of but didn’t have time to expand on:
-
PyTorch automatic differentiation which uses instrumented objects (similar to the SQLAlchemy example I presume), plus some kind of pattern matching on function calls that I haven’t had time to investigate.
Understanding Automatic Differentiation in 30 lines of Python is a great article on how you can build this kind of thing. Crucially, Python’s dynamism makes this kind of thing very accessible to mere mortals.
VCR.py: monkey patch all HTTP functions and record interactions, so that the second time we run a test we can use canned responses and avoid the network.
CCiW email tests: monkey patch Django’s Atomic decorator and mail sending functions to ensure we are using “queued email” appropriately inside transactions.
Lots of tricks in django-tagulous to improve usability for developers.
numba: JIT compile and run your Python code on a GPU with a single decorator.
drf-spectacular: iterate over all endpoints in a DRF project, introspecting serializers and calling methods with dummy request objects where necessary, to produce an OpenAPI schema.
In the stdlib, @total_ordering will look at your class and add missing rich comparison methods.
depending on an environment flag, automatically wrap all UI test cases in a decorator that takes a screenshot if the test fails.
EDIT: And some more I discovered after publishing this post, which look interesting:
Conclusion
Why don’t we talk about these much? I think a large part of the answer is that the Python community cares about solving problems, and not about how clever your code is. Clever code, in fact, is looked down on, which is the right attitude – cleverness for the sake of it is always bad. Problem solving is good though. So libraries and projects that do these things don’t tend to brag about their clever techniques, but the problem that they solve.
Also, many libraries that use these things wrap them up so that you don’t have to know what’s going on – It Just Works. As a newbie, everything about computers is magical and you have to just accept that that’s how they work. Then you take it for granted, and just get on with using it.
On the other hand, for the implementer, once you understand the magic, it stops being magic, it’s just a feature that the language has.
Either way, pretty soon none of these things count as “hyper-programming” any more – in one sense, they are just normal Python programming, and that’s the whole point: Python gives you super powers which are not super powers, they are normal powers. Everyone gets to use them, and you don’t need to learn a different language to do so.
Perhaps we do need to talk about them more, though. At the very least, I hope my examples have sparked some ideas about the kinds of things that are possible in Python.
Happy hacking!